Measurement reliability for individual differences in multilayer network dynamics:Cautions and considerations
Abstract
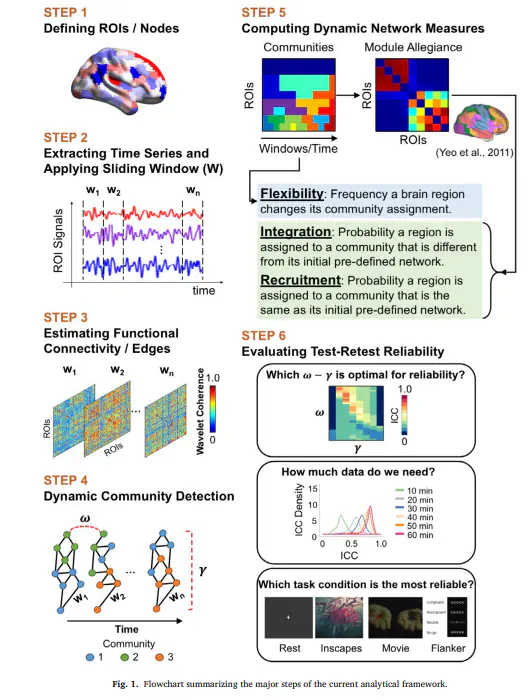
Multilayer network models have been proposed as an effective means of capturing the dynamic configuration of distributed neural circuits and quantitatively describing how communities vary over time. Beyond general insights into brain function, a growing number of studies have begun to employ these methods for the study of individual differences. However, test–retest reliabilities for multilayer network measures have yet to be fully quantified or optimized, potentially limiting their utility for individual difference studies. Here, we systematically evaluated the impact of multilayer community detection algorithms, selection of network parameters, scan duration, and task condition on test–retest reliabilities of multilayer network measures (i.e., flexibility, integration, and recruitment). A key finding was that the default method used for community detection by the popular generalized Louvain algorithm can generate erroneous results. Although available, an updated algorithm addressing this issue is yet to be broadly adopted in the neuroimaging literature. Beyond the algorithm, the present work identified parameter selection as a key determinant of test–retest reliability; however, optimization of these parameters and expected reliabilities appeared to be dataset-specific. Once parameters were optimized, consistent with findings from the static functional connectivity literature, scan duration was a much stronger determinant of reliability than scan condition. When the parameters were optimized and scan duration was sufficient, both passive (i.e., resting state, Inscapes, and movie) and active (i.e., flanker) tasks were reliable, although reliability in the movie watching condition was significantly higher than in the other three tasks. The minimal data requirement for achieving reliable measures for the movie watching condition was 20 min, and 30 min for the other three tasks. Our results caution the field against the use of default parameters without optimization based on the specific datasets to be employed – a process likely to be limited for most due to the lack of test–retest samples to enable parameter optimization.