Effective Ensemble of Deep Neural Networks Predicts Neural Responses to Naturalistic Videos
Abstract
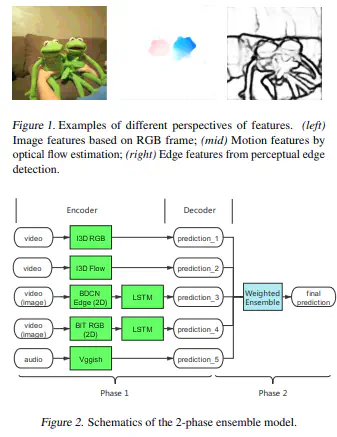
This report provides a review of our submissions to the Algonauts Challenge 2021. In this challenge, neural responses in the visual cortex were recorded using functional neuroimaging when participants were watching naturalistic videos. The goal of the challenge is to develop voxel-wise encoding models which predict such neural signals based on the input videos. Here we built an ensemble of models that extract representations based on the input videos from 4 perspectives:image streams, motion, edges, and audio. We showed that adding new modules into the ensemble consistently improved our prediction performance. Our methods achieved state-of-the-art performance on both the mini track and the full track tasks.
Type
Publication
bioRxiv