Mixmix:All you need for data-free compression are feature and data mixing
Abstract
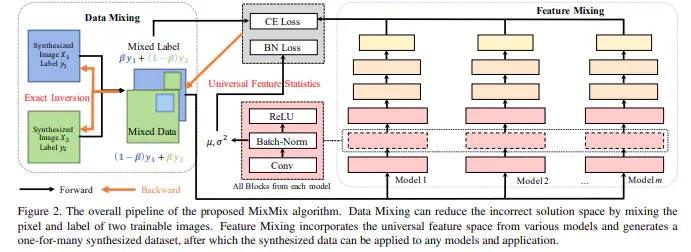
User data confidentiality protection is becoming a rising challenge in the present deep learning research. Without access to data, conventional data-driven model compression faces a higher risk of performance degradation. Recently, some works propose to generate images from a specific pretrained model to serve as training data. However, the inversion process only utilizes biased feature statistics stored in one model and is from low-dimension to high-dimension. As a consequence, it inevitably encounters the difficulties of generalizability and inexact inversion, which leads to unsatisfactory performance. To address these problems, we propose MixMix based on two simple yet effective techniques:(1) Feature Mixing:utilizes various models to construct a universal feature space for generalized inversion; (2) Data Mixing:mixes the synthesized images and labels to generate exact label information. We prove the effectiveness of MixMix from both theoretical and empirical perspectives. Extensive experiments show that MixMix outperforms existing methods on the mainstream compression tasks, including quantization, knowledge distillation and pruning. Specifically, MixMix achieves up to 4% and 20% accuracy uplift on quantization and pruning, respectively, compared to existing data-free compression work.